










مایکروسافت و انویدیا بزرگترین و قدرتمندترین مدل زبانی جهان را خلق کردند
انویدیا و مایکروسافت ۲۰ مهر ۱۴۰۰ ادعا میکنند که بزرگترین و قدرتمندترین مدل زبانی یکپارچه موجود را با عنوان مدل تولید زبان طبیعی مگاترون تورینگ (Megatron-Turing Natural Language Generation) ایجاد کردهاند.
مدل زبانی، مدلی برای تمایز بین کلمات و عباراتی است که در گفتار ممکن است مشابه به نظر برسند؛ بهعنوان مثال، در انگلیسی عبارات «recognize speech» و «wreck a nice beach» تقریبا شبیه به هم تلفظ میشوند؛ اما معانی مختلفی دارند.
مقالهی مرتبط:انویدیا چگونه در سه هفته، هفتمین رایانه سریع دنیا را تولید کرد؟
از مدلهای زبانی در تشخیص گفتار، ترجمههای ماشینی، تجزیه و تحلیل دستورهای گفتاری برای دستگاههای هوشمند، تشخیص دست خط، بازیابی اطلاعات و سایر برنامهها استفاده میشود.
مدلهای زبانی با استفاده از هوش مصنوعی به تشخیص ابهامات گفتاری مانند مثال بالا کمک خواهند کرد.
به گزارش ZDnet، مدل زبانی مگاترون تورینگ، ۱۰۵ لایه و ۵۳۰ میلیارد پارامتر دارد و روی سختافزار ابررایانهای مانند سلین (Selene) اجرا میشود.
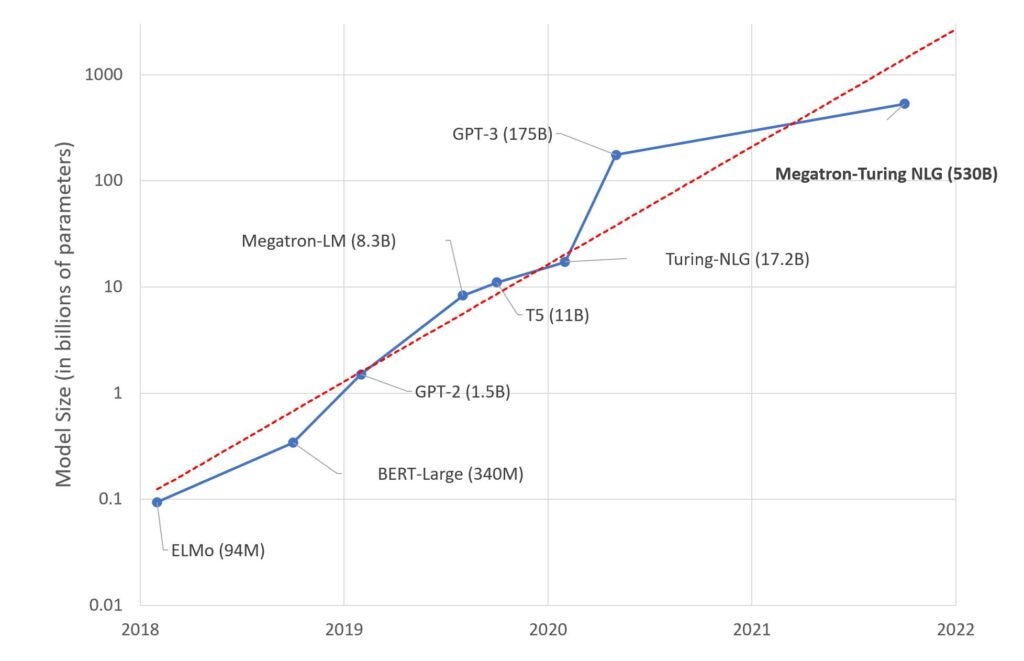
برای اینکه درک بهتری از قدرت این مدل زبانی داشته باشیم، میتوان آن را با مدل زبانی GPT-3 مقایسه کرد. GPT-3 مدل زبانی خودهمبستهای است که از یادگیری عمیق برای تولید محتوای متنی شبیه به انسان استفاده میکند؛ این مدل ۱۷۵ میلیارد پارامتر دارد.
مایکروسافت و انویدیا مشخصات این مدل زبانی را اینگونه توضیح دادهاند:
هر ماکت این مدل زبانی مجهز به ۲۸۰ پردازنده گرافیکی A100 انویدیا است که هر گره، برش خاص ۸ سویه دارد و در کل گرهها ۳۵ مسیر موازی پردازش دیده شده است.
این مدل زبانی روی ۱۵ مجموعه داده با ۳۳۹ میلیارد توکن آموزش دیده و قادر است توضیح بدهد که چرا هرچه مدل بزرگتر باشد برای عملکرد بهتر آموزش کمتری نیاز خواهد داشت.
اما مدل مگاترون تورینگ مانند همه مدلهای زبانی، در بهکارگیری هوش مصنوعی با خطاهای سیستماتیکی همراه است.
مایکروسافت و انویدیا درباره مشکلات مدلهای زبانی گفتند:
مدلهای قدرتمند زبانی هر روز بیشتر از قبل پیشرفت میکنند؛ اما هنوز برخی از خطاهای سیستماتیک وجود دارد. طبق مشاهدات ما، کلیشههای زبانی باعث ایجاد این خطاها در هوش مصنوعی بهکاررفته در مدل زبانی مگاترون تورینگ میشوند و ما خود را متعهد میدانیم تا راه حلی برای این مشکل ارائه کنیم.
مقالهی مرتبط:درسهایی که مایکروسافت از بات هوش مصنوعی Tay گرفت
مایکروسافت در سال ۲۰۱۶ (۱۳۹۵) با استفاده از فناوری یادگیری ماشین، فعالیت باتی به نام Tay را در توییتر آغاز کرد تا تعامل آن را با انسانها آزمایش کند؛ اما این بات در کمتر از ۲۴ ساعت، ادبیاتش تغییر و توییتهایی نژادپرستانهای منتشر کرد.
شما تابهحال چه مشکلاتی با مدلهای زبانی بهکاررفته در دستیارهای صوتی اطراف خود مشاهده کردهاید؟
مایکروسافت با همکاری انویدیا، مدل زبانی قدرتمندی با ۱۰۵ لایه و ۵۳۰ میلیارد پارامتر ایجاد کرده؛ این مدل زبانی مجهز به ۲۸۰ پردازنده گرافیکی A100 انویدیا است.