










انویدیا از سوپرتراشهی ۱۴۴ هستهای Grace رونمایی کرد
جنسن هوانگ، مدیرعامل انویدیا، در رویداد GTC ۲۰۲۲ که در تاریخ ۲ فروردین ۱۴۰۱ برگزار شد، سرانجام جزئیات بیشتری را در مورد دستاوردهای جدید این شرکت در رابطه با معماری آرم به اشتراک گذاشت. تیم سبز در این رویداد از سوپرتراشهی ۱۴۴ هستهای Grace خود رونمایی کرد؛ این پردازنده اولین تراشهی مبتنی بر معماری آرم انویدیا است که برای استفاده در مراکز داده طراحی شده است.
سوپرتراشهی Grace از سیستم مبتنی بر Neoverse آرم v9 پشتیبانی میکند و از ترکیب دو تراشه با فناوری اتصال جدید NVLink-C2C ایجاد شده است. انویدیا ادعا میکند که عملکرد سوپرتراشهی Grace در بنچمارک SPEC تا ۱٫۵ برابر نسبت به دو پردازندهی ۶۴ هستهای نسل قبلی EPYC ایام دی بهتر است و همچنین نسبت به تراشههای سرور پیشروی امروزی دو برابر مصرف انرژی بهینهتری دارد.
بهطور کلی، انویدیا ادعا میکند که سوپرتراشهی Grace در زمان عرضه در اوایل سال ۲۰۲۳ (زمستان ۱۴۰۱) سریعترین پردازنده در بازار خواهد بود که برای طیف گستردهای از برنامهها مانند محاسبات در مقیاس بزرگ، تجزیه و تحلیل دادهها و محاسبات علمی عرضه میشود.
مقالهی مرتبط:نقشه راه بلندمدت انویدیا برای ساخت پردازندههای مبتنی بر آرم
با توجه به آنچه در مورد نقشه راه معماری آرم میدانیم، سوپرتراشهی CPU Hopper براساس پلتفرم N2 Perseus، اولین پلتفرمی است که از معماری آرم v9 پشتیبانی میکند. این پلتفرم با لیتوگرافی ۵ نانومتری عرضه میشود و از آخرین فناوریهای ارتباطی مانند PCIe نسل ۵، DDR5، HBM3، CCIX 2.0 و CXL 2.0 پشتیبانی میکند و نسبت به پلتفرم V1 تا ۴۰ درصد عملکرد بیشتری ارائه میکند.
انویدیا همچنین جزئیات جدیدی در مورد سوپرتراشهی Grace Hopper، تراشهای شامل پردازنده و پردازندهی گرافیکی که قبلا معرفی شده بود، به اشتراک گذاشت و رابط جدید تراشه به تراشه NVLink-C2C خود را معرفی کرد. این رابط جدید اتصال داخلی دای به دای (Die to Die) و تراشه به تراشهای است که از هماهنگی حافظه پشتیبانی میکند.
دای، در مباحث مربوط به مدارهای مجتمع، به سطحی از مادهی نیمهرسانا میگویند که مدار روی آن ساخته میشود.
رابط NVLink-C2C میتواند با بهرهمندی از ۹۰۰ گیگابایتبرثانیه توان عملیاتی یا بیشتر، تا ۲۵ برابر بازده انرژی بیشتری ارائه دهد و ۹۰ برابر کمتر از لایهی سیگنالدهی سطح پایین PCIe نسل ۵ فعلی انویدیا فضا اشغال کند. این رابط از پروتکلهای استاندارد صنعتی مانند CXL و AMBA CHI آرم پشتیبانی میکند و از اتصالات مبتنی بر PCB تا پلهای سیلیکونی برای عبور سیگنالهای الکتریکی و پیادهسازی در مقیاس ویفر پشتیبانی میکند.
رابط NVLink-C2C از مشخصات سیستم چیپلت اتصال سریع جهانی(UCIe) پشتیبانی خواهد کرد و در کمال تعجب، به نظر میرسد که انویدیا قصد دارد به دیگر فروشندگان نیز اجازه دهد تا از این طراحی استفاده کنند.
سیستم چیپلت اتصال سریع جهانی(UCIe) کنسرسیوم جدیدی است که برای ادغام چیپلتها با یکدیگر در طراحی نیمههادیها و استانداردسازی اتصالات بین چیپلتها با طراحی منبع باز معرفی شده است و کاهش هزینهها و تقویت اکوسیستم گستردهتری از چیپلتهای معتبر را به ارمغان میآورد. در ادامه جزئیات بیشتری از این سوپرتراشه را بررسی خواهیم کرد:
سوپرتراشهی پردازندهی Grace انویدیا
انویدیا فروردین ۱۴۰۰ برای اولین بار پردازندهای مرکزی به نام Grace را بی اینکه جزئیات دقیقی از آن را به اشتراک بگذارد، معرفی کرد. تیم سبز حالا نام این پردازنده را به Grace Hopper تغییر داده است.

پردازندهی Grace Hopper به دو تراشهی متمایز، یک پردازنده و یک پردازندهی گرافیکی مجهز است که روی یک برد حامل قرار گرفتهاند. پردازندهی گرافیکی این محصول از ۷۲ هسته و طراحی مبتنی بر Neoverse بهرهمند است که از v9 آرم پشتیبانی میکند و با یک پردازندهی گرافیکی Hopper جفت شده است. این دو تراشه ازطریق اتصال ۹۰۰ گیگابایتبرثانیهای NVLink-C2C ارتباط برقرار میکنند و با هماهنگی حافظه بین پردازنده و پردازندهی گرافیکی، هر دو واحد میتوانند بهطور همزمان به حافظهی LPDDR5X ECC دسترسی داشته باشند؛ ادعا میشود این حافظه، پهنای باند ۳۰ برابری نسبت به سیستمهای استاندارد دراختیار میگذارد.
انویدیا میزان فضای حافظهی LPDDR5X مورد استفاده در این طراحی را۶۰۰ گیگابایت عنوان کرده است. با توجه به اینکه هر واحد LPDDR5X حداکثر ۶۴ گیگابایت فضا ارائه میدهد، پردازندهی این سوپرتراشه حداکثر ۵۱۲ گیگابایت LPDDR5X عرضه میکند؛ از سوی دیگر پردازندهی گرافیکی Hopper نیز معمولاً ۸۰ گیگابایت ظرفیت HBM3 دارد که مجموع این اعداد و ارقام همان عدد ۶۰۰ گیگابایتی ادعا شده توسط انویدیا را تأیید میکند. دسترسی داشتن پردازندهی گرافیکی به این مقدار از ظرفیت حافظه میتواند برای انجام برخی کارها، مخصوصا اجرای برنامههای بهینهسازی شده، تأثیری دگرگونکننده داشته باشد.
به گزارش Tomshardware و طبق گفتهی انویدیا، تیم سبز در سوپرتراشهی Grace به جای استفاده از دو تراشه (پردازندهی Grace Hopper و پردازندهی گرافیکی)، با جایگزینی پردازندهی گرافیکی با پردازندهی مرکزی دیگر، از دو واحد پردازنده استفاده کرده است. این دو تراشه به ۷۲ هسته مجهز هستند که ازطریق رابط NVLink-C2C به هم متصل میشوند و با بهرهمندی از ۱۴۴ هسته، نرخ انتقال دادهی ۹۰۰ گیگابایتبرثانیهای فراهم میکنند.

علاوه بر این، تراشه مبتنی بر معماری v9 Neoverse آرم از افزونههای برداری مقیاسپذیر (SVE) این معماری پشتیبانی میکند؛ این افزونهها اجرای دستورالعملها (SIMD) را تقویت میکنند و عملکردی مشابه AVX دارند.
با توجه به اینکه سوپرتراشهی Grace از v9 آرم استفاده میکند، میتوان گفت که این محصول مبتنی بر معماری Neoverse N2 یا همان Perseus تولید شده است؛ پلتفرم Neoverse N2 اولین IP آرم است که از افزونههای v9 مانند SVE2 و Memory Tagging پشتیبانی میکند و تا ۴۰ درصد نسبت به پلتفرم V1 عملکرد بهتری دارد. این پلتفرم با طراحی ۵ نانومتری عرضه میشود و از فناوری PCIe نسل ۵، DDR5، HBM3، CCIX 2.0 و CXL 2.0 پشتیبانی میکند.
ازآنجاکه پلتفرم Neoverse N2 برای انجام هر عملکردی بهینهسازی شده است؛ حداکثر مصرف برق ۵۰۰ واتی برای هر دو پردازنده و ماژول حافظهی سوپرتراشهی Grace منطقی به نظر میرسد و آن را به رقیبی قدرتمند برای پردازندههای پیشرو در بازار مانند EPYC ایامدی تبدیل میکند. پردازندهی EPYC به تنهایی تا ۲۸۰ وات به ازای هر تراشه برق مصرف میکند و حالا انویدیا با معرفی سوپرتراشهی Grace ادعا میکند که این محصول از پردازندههای رقیب در بازار دو برابر کارآمدتر خواهد بود.
مقالههای مرتبط:پردازنده مرکزی Nvidia Grace بر پایه ARM معرفی شد؛ ۱۰ برابر قویتر از x86پتنت AMD به طراحی چیپلت در پردازندههای گرافیکی اشاره میکند
هر پردازنده در سوپرتراشهی Grace به هشت بستهی LPDDR5X خود دسترسی دارد و هر دو تراشه از فناوری NUMA (دسترسی غیریکنواخت به حافظه) بهره میبرد. از طرفی افزایش پهنای باند بین دو تراشه، تأخیر را کاهش داده و اتصال چندتراشهای بسیار کارآمدی را ایجاد میکند. این محصول ۳۹۶ مگابایت حافظه نهان نیز دارد که هنوز مشخص نیست به یک تراشه اختصاص دارد یا هر دو.
سابسیستم حافظهی سوپرتراشهی Grace حداکثر یک ترابایتبرثانیه پهنای باند را در ۱۶ بسته ارائه میدهد که به ادعای انویدیا این مقدار تا بهحال در هیچ پردازندهای وجود نداشته است و از دو برابر پهنای باند ارائه شده در دیگر پردازندههای مرکزی که از حافظهی DDR5 پشتیبانی میکنند نیز بیشتر است. علاوه بر این، انویدیا اشاره میکند که سوپرتراشهی Grace از اولین پیادهسازی الگوریتم اصلاح خطای LPDDR5X استفاده میکند.
در مورد بنچمارکهای انجام شده، انویدیا ادعا میکند که سوپرتراشهی Grace در بنچمارک SPECrate_2017_int_base تا ۱٫۵ برابر از دو پردازندهی ۶۴ هستهای نسل قبلی EPYC Rome 7742 سریعتر است. البته ادعای تیم سبز بر شبیهسازیها استوار است و امتیاز Grace را رقمی بیش از ۷۴۰ (۳۷۰ برای هر تراشه) پیشبینی میکند. امتیاز پردازندهی نسل فعلی EPYC Milan ایامدی بین ۳۸۲ تا ۴۲۴ عنوان شده است که نشان میدهد تراشههای x86 همچنان بالاترین رتبه را در این زمینه خواهند داشت. بااینحال، راهحل انویدیا مزایای بسیارِ دیگری مانند بهره وری انرژی و طراحی سازگارتر با پردازندهی گرافیکی خواهد داشت.
دو سوپرتراشهی Grace ازطریق رابط جدید تراشه به تراشهی NVLink-C2C انویدیا ارتباط برقرار میکنند. این اتصال داخلی از هماهنگی حافظه با تأخیر کم پشتیبانی میکند و به هر دو طرف اتصال اجازه میدهد بهطور همزمان روی یک مخزن حافظه کار کنند. انویدیا این رابط را با استفاده از فناوریهای طراحی SERDES و LINK با تمرکز بر بهرهوری انرژی و منطقه ایجاد کرده است.
فناوری SerDes یا Serializer/Deserializer معمولاً در ارتباطات پرسرعت برای جبران محدودیت ورودی/خروجی و انتقال داده ازطریق یک خط یا یک جفت دیفرانسیل به منظور به حداقل رساندن تعداد پینها و اتصالات ورودی/خروجی استفاده میشود.
انویدیا میگوید رابط NVLink-C2C میتواند تا ۲۵ برابر بازده انرژی بیشتری ارائه دهد، ۹۰ برابر کمتر از لایهی سیگنالدهی سطح پایین PCIe نسل ۵ فعلی انویدیا، فضا اشغال کند و نرخ انتقال دادهی تا ۹۰۰ گیگابایتبرثانیه و بیشتر داشته باشد. این رابط همچنین از پروتکلهای استاندارد صنعتی مانند CXL برای پردازش مرکزی پرسرعت و رابط هاب منسجم AMBA آرم برای اتصال و مدیریت بلوکهای عملکردی در یک تراشه استفاده کرده و در عین حال از اتصالات مبتنی بر PCB گرفته تا پلهای سیلیکونی برای عبور سیگنالهای الکتریکی و پیادهسازی در مقیاس ویفر نیز پشتیبانی میکند.
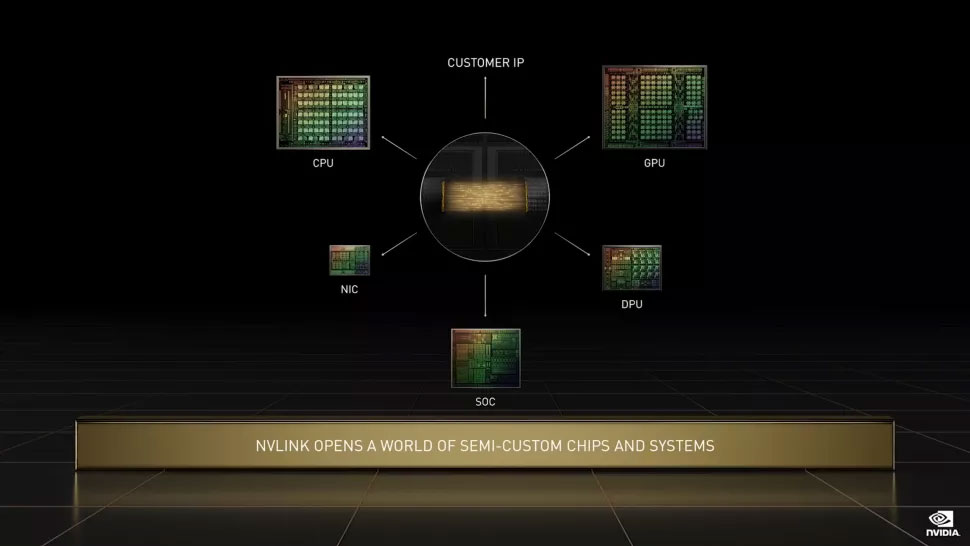
انویدیا همچنین اعلام کرد این سوپرتراشه از استاندارد جدید اتصال تراشههای UCIe پشتیبانی میکند که توسط سایر تولیدکنندههای بزرگ مانند اینتل، ایامدی، آرم، TSMC و سامسونگ تأیید میشود و با توجه به اینکه این اتصال متقابل استاندارد شده برای ایجاد ارتباط بین تراشهها با طراحی منبع باز طراحی شده است، هزینهها را کاهش میدهد و اکوسیستم گستردهتری از تراشههای معتبر را تقویت میکند.
حمایت انویدیا از این ابتکار میتواند نشاندهندهی این امر باشد که امکان استفادهی دیگر رقبا نیز از این فناوری وجود دارد.
حالا رابط NVLink-C2C به تمام سیلیکونهای انویدیا، مانند پردازندههای گرافیکی، پردازندههای مرکزی، تراشهها، کارتهای رابط شبکه و واحدهای پردازش داده گسترش خواهد یافت و با توجه به متن باز بودن این رابط، سایر شرکتها نیز اجاره خواهند داشت تا از NVLink در طراحی چیپلتهای خود استفاده کنند.

همانطورکه در تصویر بالا مشاهده میکنید، سیستمهای سوپرتراشهی Grace Hopper و سوپرتراشهی Grace میتوانند در چندین پیکربندی مختلف با حداکثر هشت پردازنده گرافیکی Hopper ترکیب شوند. این طرحها از کارت رابط شبکهی هوشمند انویدیا استفاده میکنند که ارتباط NVLink را ازطریق سوئیچ داخلی PCIe نسل ۵ برقرار میکند و با این کار امکان پشتیبانی گستردهتری از برنامههای سیستم به سیستمی فراهم خواهدشد.
انویدیا در حال حاضر تلاش میکند تا بازارهای هدف خود را با سوپرتراشهی Grace گسترش دهد و بهطور مؤثر بازار سرورهای همه منظوره را هدف قرار میدهد. سوپرتراشهی Grace انویدیا از مدل برنامهنویسی CUDA پشتیبانی کرده و طیف کاملی از برنامههای تیم سبز مانند Nvidia RTX، Nvidia AI، HPC و Omniverse را اجرا میکند؛ عرضه این محصول از نیمهی اول سال ۲۰۲۳ (زمستان ۱۴۰۱) آغاز خواهد شد.
انویدیا بهطور گسترده به صنعت تولید پردازنده وارد میشود؛ تیم سبز ادعا میکند سوپرتراشهی Grace مبتنی بر معماری آرم تا ۱٫۵ برابر از EPYC Rome ایامدی سریعتر است.